学习目标
- 了解
RNA-seq count 数据的特征
- 比较
count 数据的不同数学模型
- 确定最适合
RNA-seq count 数据的模型
- 了解设置生物学重复对于鉴定样本间差异的好处
1. 计数矩阵
当开始差异表达基因分析时,先从一个矩阵开始,该矩阵总结了数据集每个样本中的基因水平表达。矩阵中的行对应基因,列对应样本。在矩阵的每个位置,有一个整数值,表示源自样本中特定基因的序列读取总数(如下图)。

计数越高表明与该基因相关的读数越多,表明该基因的表达水平越高。然而,这不一定是真的,我们将在本课和课程的后面深入探讨这一点。
2. 数据特征
为了了解 RNA-seq 计数是如何分布的,让我们绘制单个样本 Mov10_oe_1 的计数直方图:
ggplot(data) +
geom_histogram(aes(x = Mov10_oe_1), stat = "bin", bins = 200) +
xlab("Raw expression counts") +
ylab("Number of genes")
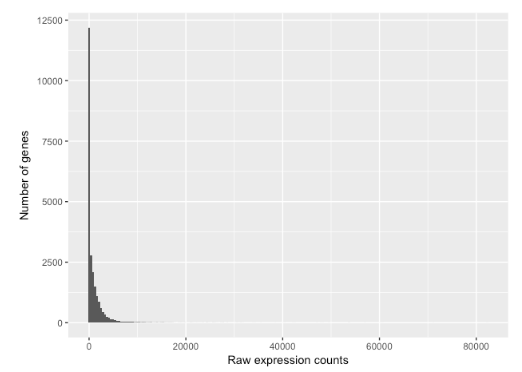
上图展示了一些 RNA-seq count 数据的共有特征:
- 与大部分基因相关的计数较少
- 由于没有设置表达上限,因此直方图右方有很长的尾巴
- 数据的变化范围很大
查看直方图的形状,发现它不是正态分布的。对于 RNA-seq 数据,情况总是如此。此外,正如我们之前观察到的,数据是整数计数而不是连续测量。在决定使用哪种统计模型时,我们需要考虑这些特征。
3. 数据建模
计数数据一般可以用各种分布建模:
那么应该选择那一个呢?
在 RNA-seq 数据中,代表了非常多的 RNA,提取出特定转录本的概率非常小。这种情况泊松分布可能是最合适的。然而,这还取决于我们数据中均值和方差之间的关系。
3.1. 均值与方差
为了评估正在处理的数据的特征,可以使用与 Mov10 过表达”对应的三个重复样本。
首先计算样本的均值,再计算方差,最后通过作图的方法,确定它们之间的关系。
# 均值
mean_counts <- apply(data[,6:8], 1, mean)
# 方差
variance_counts <- apply(data[,6:8], 1, var)
# 构建data.frame
df <- data.frame(mean_counts, variance_counts)
# 可视化
ggplot(df) +
geom_point(aes(x=mean_counts, y=variance_counts)) +
scale_y_log10(limits = c(1,1e9)) +
scale_x_log10(limits = c(1,1e9)) +
geom_abline(intercept = 0, slope = 1, color="red")
图应该类似于下面的散点图。每个数据点代表一个基因,红线代表 x = y。
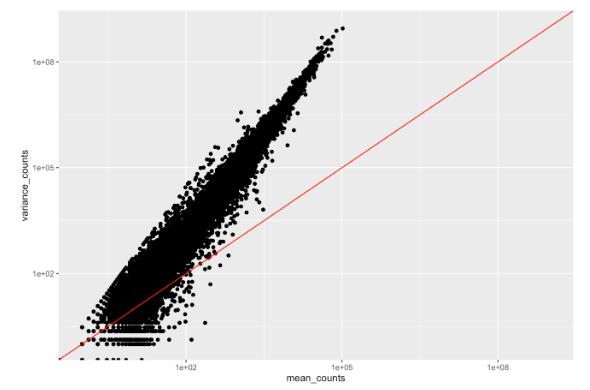
- 均值不等于方差(数据点的散布不在对角线上)。
- 对于具有高平均表达的基因,重复之间的方差往往大于平均值(散点在红线上方)。
- 对于平均表达较低的基因,相当分散。我们通常将其称为“异方差性”。也就是说,对于低范围内的给定表达水平,我们观察到方差值有很多可能性。
4. 重复与差异
生物重复代表对应于同一样本类别或组的多个样本(即来自不同小鼠的 RNA)。直觉上,我们期望来自同一样本组的样本(即在相似条件或扰动下的样本)表现出相似的转录谱。大多数情况下,一个组内的样本会有很高的相似度,但也难免会有很多差异。基因表达的这种差异的来源可以归因于许多因素,其中一些是可知的,而另一些则仍然未知。
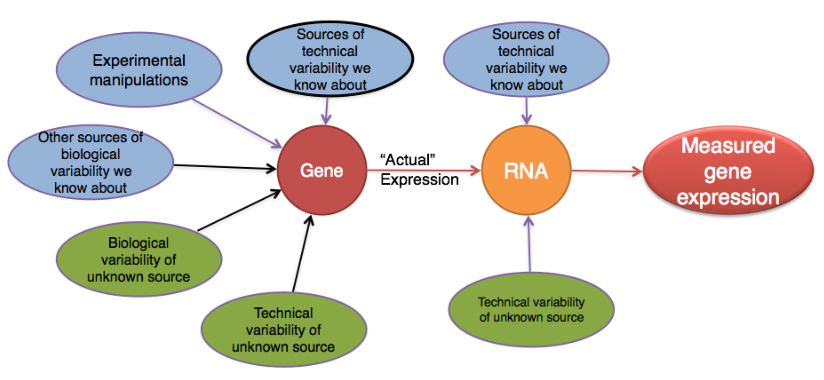
通过差异表达分析,我们寻找在两个或多个组之间表达发生变化的基因。例如,
- 处理 vs. 对照
- 表达与某些变量或临床结果的相关性
但是,数据发生的变化比预期的要多得多。表达水平不同的基因不仅是实验的结果,也可能是外部原因的结果。差异表达分析的目标是识别和纠正差异来源,以便我们可以将 interesting 与 uninteresting 区分开来。
此处绘制了“未处理”和“处理”组中 GeneA 的表达(计数)。每个点对应于单个样本的表达,并且根据它们属于哪个组对点进行着色。
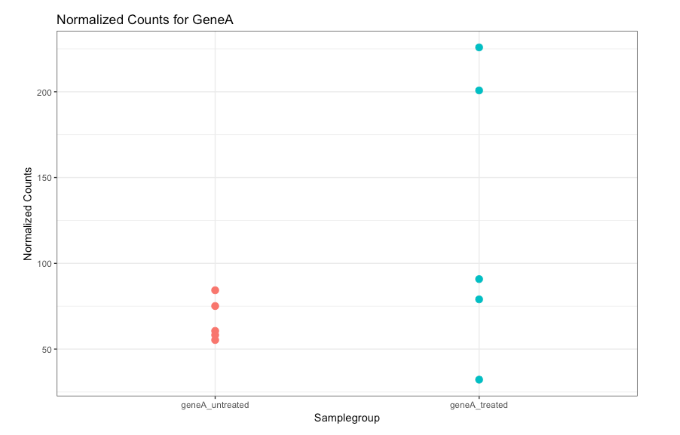
“处理”组 GeneA 的平均表达水平是“未处理”组的两倍。但是考虑到组内观察到的差异(跨重复),组间表达的差异是否显著?
差异可能实际上并不显著。在确定基因是否差异表达时,我们需要考虑数据的变化(以及它可能来自哪里)。使用负二项分布对我们的数据建模使我们能够做到这一点。
4.1. 重复数
那么应该设置多少个重复呢?
多总是更好!我们建议每个样品组至少重复三次,但如果您可以将其增加任意数量,那更好。重复的价值在于,随着您添加更多数据,将获得越来越精确的组均值估计,并最终更有信心,可靠地区分样本类别之间的差异。
更多重复的作用:
- 估计每个基因的差异
- 随机化出未知的协变量
- 发现异常值
- 提高表达和变化估计的精度
下图评估了测序深度和重复次数对差异表达基因数量关系
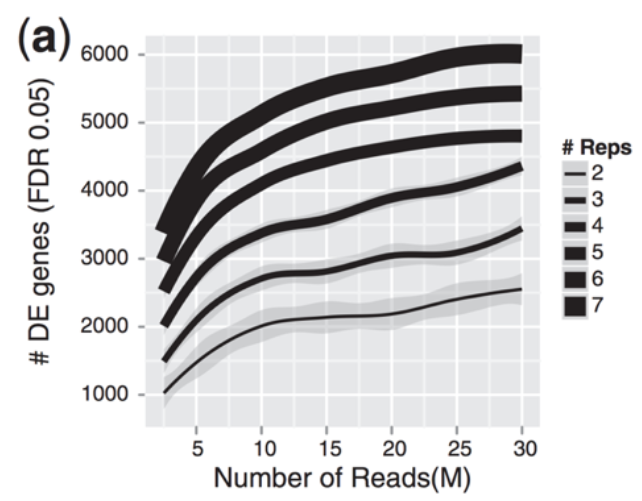
请注意,与增加测序深度相比,重复次数的增加往往会返回更多的差异表达基因。因此,通常更多的重复比更高的测序深度更好,但需要注意的是,检测低表达的差异表达基因和执行异构体水平的差异表达需要更高的深度。
5. DESeq2
DESeq2 是一种流行的基因水平差异表达分析工具。它使用负二项分布,与某些方法相比采用了稍微更严格的方法,但在灵敏度和特异性之间取得了良好的平衡(减少了假阳性和假阴性)。
我们将在本教程中使用 DESeq2 进行分析。
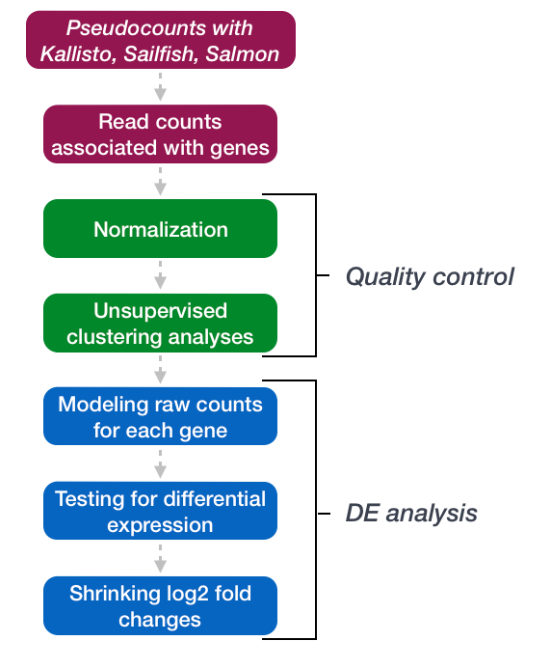
进行分析。 DESeq2 的分析步骤在下面的流程图中以绿色和蓝色显示。








 苏公网安备32011502012024号
苏公网安备32011502012024号