学习目标
- 了解
RNA-seq 和差异表达基因的分析流程
- 了解如何设计实验
- 了解如何使用
R 语言进行数据分析
1. 简介
在过去的十年中,RNA-seq 已成为转录组差异表达基因和 mRNA 可变剪切分析不可或缺的技术。正确识别哪些基因或转录本在特定条件下的表达情况,是理解生物反应过程的关键。
在本教程中,将借助许多R包,带你进行一个完整的 RNA-seq 分析过程。将从读取数据开始,将伪计数转换为计数,执行数据分析以进行质量评估并探索样本之间的关系,执行差异表达分析,并在执行下游功能分析之前直观地查看结果。下面是流程图。
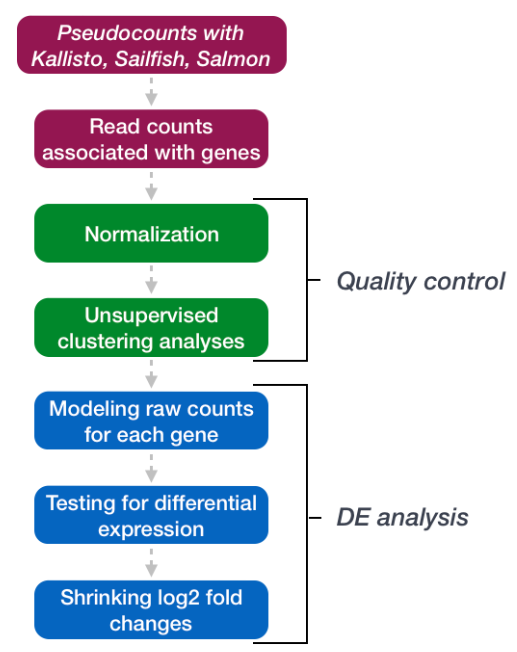
2. 数据集
本教程将使用Kenny PJ et al, Cell Rep 2014 中的一部分数据进行演示。实验是在
中的一部分数据进行演示。实验是在 HEK293F细胞中进行的,这些细胞,进行了 MOV10基因的转染,或敲除了 MOV10基因,使得 MOV10基因的表达将发生变化。具体情况如下:
| 处理 |
1 |
2 |
3 |
| MOV10 gene |
over expression |
knock down |
Irrelevant siRNA |
|
过表达 |
敲除 |
对照 |
重复的情况如下图:
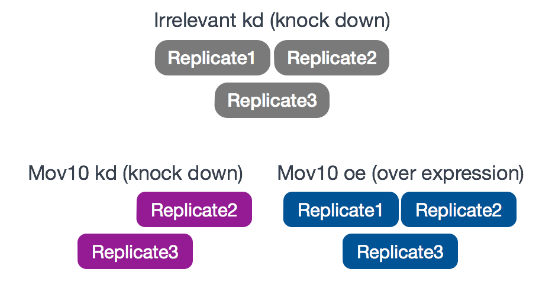
使用这些数据,我们将探究 MOV10 基因表达出现不同的转录模式。此数据集的原始序列是从 Sequence Read Archive (SRA) 获得的。然后经过之前介绍的工具,进行处理。所有的操作都是在 (Linux/Unix) 环境进行的。
MOV10:是一种 RNA 解旋酶,在 microRNA 通路的背景下与性别相关发育有关。
3. 问题
MOV10 基因的表达变化会产生什么影响?- 变化之间是否有共同的特征?
4. 配置
打开 RStudio 并为此分析创建一个新项目。
- 转到
File 菜单并选择 New Project。
- 选择
New Directory ,然后创建 DEanalysis目录。
RStudio 会自动打开该项目。
使用 getwd(),检查是否在正确的工作目录中。返回的结果应该是:path/DEanalysis
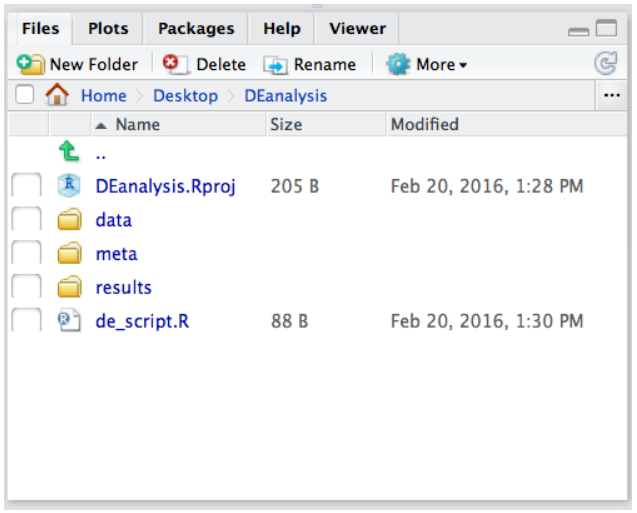
(考虑到每个人的路径不同,因此只需要最后是 /DEanalysis即可)。在您的工作目录中,创建两个新目录:meta 和 results。
现在我们需要获取用于分析的文件:Mov10,点击即可下载(不能下载的,可以在文末链接获取)。下载 zip 文件后,您需要解压它。将创建一个 data 目录,其中的子目录对应于我们数据集中的每个样本。
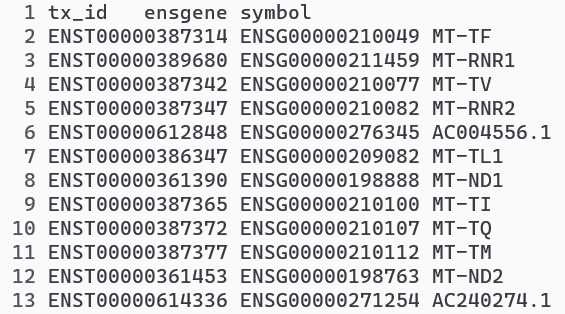
接下来,我们将下载annotation file 用于将转录本标识符转换为基因名称(如下图)。此文件是从 R 包 AnnotationHub 得到的(后续将介绍如何获取过程)。
然后用 RStudio 打开之前的 DEanalysis目录,创建一个 de_script.R 文件,写入下面的注释,并保存。
## Gene-level differential expression analysis using DESeq2
## 使用 DESeq2 进行差异表达基因分析
完成以上步骤后,最后的工作目录如下图:
5. 加载包
分析将使用几个 R 包,一些是从 CRAN 安装的,另一些是从 Bioconductor 安装的。要使用这些包,需要加载包。将以下内容添加到脚本中。
library(DESeq2)
library(tidyverse)
library(RColorBrewer)
library(pheatmap)
library(DEGreport)
library(tximport)
library(ggplot2)
library(ggrepel)
6. 数据导入
Salmon 的主要输出是一个 quant.sf 文件,数据集中的每个样本都有一个这样的文件。该文件如下图所示:

- 转录本标识符
- 转录本长度
- 有效长度(
effective length)
- TPM(
transcripts per million),使用有效长度计算
- 估计的计数
effective length:
The sequence composition of a transcript affects how many reads are sampled from it. While two transcripts might be of identical actual length, depending on the sequence composition we are more likely to generate fragments from one versus the other. The transcript that has a higer likelihood of being sampled, will end up with the larger effective length. The effective length is transcript length which has been “corrected” to include factors due to sequence-specific and GC biases.
将使用 tximport 包来为 DESeq2 准备 quant.sf文件。需要做的第一件事是创建一个变量,其中包含每个 quant.sf 文件的路径。然后将名称添加到我们的 quant 文件中,这将使我们能够轻松区分最终输出矩阵中的样本。
## 列出所有文件
samples <- list.files(path = "./data", full.names = T, pattern="salmon$")
## 获取文件名和路径的向量
files <- file.path(samples, "quant.sf")
## 为每个文件单独命名
names(files) <- str_replace(samples, "./data/", "") %>%
str_replace(".salmon", "")
Salmon 索引是使用 Ensembl ID 列出的转录序列生成的,但 tximport 需要知道这些转录本来自哪些基因。我们将使用下载的 annotation file 来提取转录本的基因信息。
# 加载注释文件
tx2gene <- read.delim("tx2gene_grch38_ens94.txt")
# 查看
tx2gene %>% View()
tx2gene 是一个3列的 data frame,包含:转录本 ID;基因 ID;基因 symbol。
tximport() 函数从各种外部软件(例如 Salmon、Kallisto)导入转录水平计数,并汇总到基因水平或输出转录水平矩阵。有可选的参数来使用出现在 quant.sf 文件中的丰度估计值或计算替代值。
对于我们的分析,需要基因水平的非标准化或“原始”计数估计来执行 DESeq2 分析。由于基因计数矩阵是默认值,因此我们只需修改一个附加参数即可指定获取“原始”计数值。 countsFromAbundance 的选项如下:
no(默认):这将采用 TPM 中的值(作为我们的缩放值)和 NumReads(作为我们的“原始”计数)列,并将其折叠到基因级别。scaledTPM:这是将 TPM 放大到文库大小作为“原始”计数。lengthScaledTPM:这用于从 TPM 生成“原始”计数表。 “原始”计数值是通过使用 TPM 值 x featureLength x 文库大小生成的。这些代表与原始计数在同一尺度上的数量。
TPM 计算过程:
reads per kilobase (RPK):将读取计数除以每个基因的长度(以千碱基为单位)“per million” scaling factor:计算样本中的所有 RPK 值并将此数字除以 1,000,000。- 将 RPK 值除以
“per million” scaling factor。
# 运行 `tximport`
txi <- tximport(files, type="salmon", tx2gene=tx2gene[,c("tx_id", "ensgene")], countsFromAbundance="lengthScaledTPM")
7. 数据检视
txi 对象是一个简单的列表,其中包含丰度、计数和长度的矩阵。另一个列表元素 countsFromAbundance 携带 tximport 中使用的字符参数。长度矩阵包含每个基因的平均转录本长度,可用作基因水平分析的偏移量。
attributes(txi)
$names
[1] "abundance" "counts" "length" [4] "countsFromAbundance"
我们将按原样使用 txi 对象作为 DESeq2 的输入,但会将其保存到下一课。现在让我们看一下计数矩阵。你会注意到有十进制值,所以让我们四舍五入到最接近的整数并将其转换为 dataframe。
# 查看 count
txi$counts %>% View()
# 将 count 写入到对象
data <- txi$counts %>%
round() %>%
data.frame()








 苏公网安备32011502012024号
苏公网安备32011502012024号