导读
本文将介绍机器学习中的 K-最近邻算法,K-Nearest Neighbors 是一种机器学习技术和算法,可用于回归和分类任务。
1. 简介

k-最近邻算法,也称为 kNN 或 k-NN,是一种非参数、有监督的学习分类器,它使用邻近度对单个数据点的分组进行分类或预测。虽然它可以用于回归问题,但它通常用作分类算法,假设可以在彼此附近找到相似点。
对于分类问题,根据比重分配类别标签,即使用在给定数据点周围最多表示的标签。虽然这在技术上被认为是 plurality voting(多数表决),但 majority vote一词在书面语中更常用。这些术语之间的区别在于,majority voting在技术上需要超过 50% ,这主要适用于只有两个类别的情况。当您有多个类别时 - 例如四个类别,您不一定需要 50% 才能对一个类别做出结论;您可以分配一个占比超过 25% 的类别标签。Wisconsin-Madison大学用了一个例子很好地总结了这一点。
回归问题使用与分类问题类似的概念,但在这种情况下,取 k 个最近邻的平均值来对分类进行预测。主要区别是分类用于离散值,而回归用于连续值。但是,在进行分类之前,必须定义距离。欧几里得距离是最常用的,我们将在下面深入研究。
值得注意的是,kNN 算法也是 lazy learning模型家族的一部分,这意味着所有计算都发生在进行分类或预测时。由于它严重依赖内存来存储其所有训练数据,因此也称为基于实例或基于内存的学习方法。
Evelyn Fix 和 Joseph Hodges 在 1951 年的这篇论文中提出了围绕 kNN 模型的最初想法,而 Thomas Cover 在他的研究中扩展了他们的概念,“Nearest Neighbor Pattern Classification”。虽然它不像以前那么受欢迎,但由于其简单性和准确性,它仍然是人们在数据科学中学习的首批算法之一。然而,随着数据集的增长,kNN 变得越来越低效,影响了模型的整体性能。它通常用于简单的推荐系统、模式识别、数据挖掘、金融市场预测、入侵检测等。
2. 距离度量
kNN距离指标计算
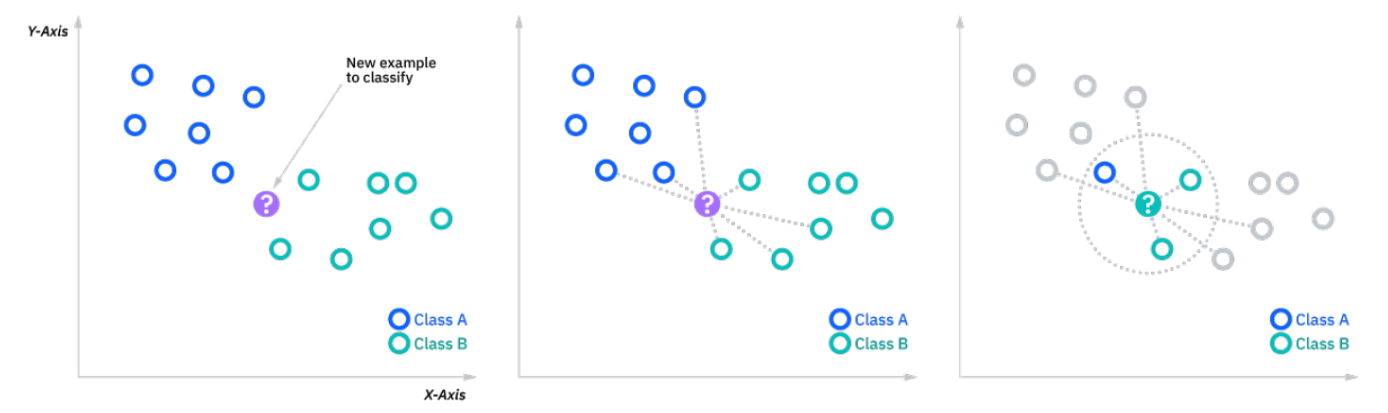
回顾一下,k-最近邻算法的目标是识别给定查询点的最近邻,以便我们可以为该点分配一个类标签。为了做到这一点,kNN 有几个要求:
为了确定哪些数据点最接近给定查询点,需要计算查询点与其他数据点之间的距离。这些距离度量有助于形成决策边界,将查询点划分为不同的区域。您通常会看到使用 Voronoi 图可视化的决策边界。
虽然您可以选择多种距离度量,但本文仅涵盖以下内容:
欧几里得距离(p=2):这是最常用的距离度量,仅限于实值( real-valued )向量。使用下面的公式,它测量查询点和被测量的另一个点之间的直线。
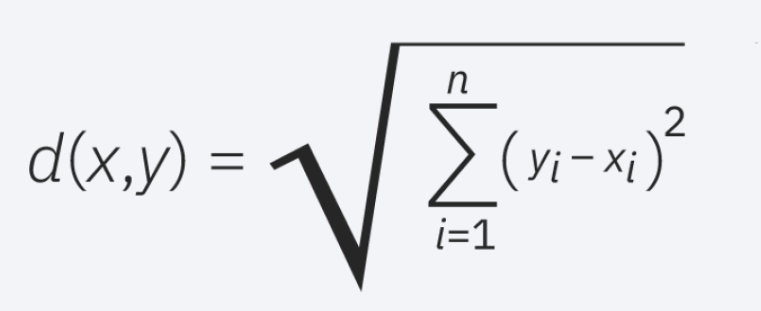
曼哈顿距离(p=1):这也是另一种流行的距离度量,它测量两点之间的绝对值。它也被称为出租车(taxicab)距离或城市街区(city block)距离,因为它通常用网格可视化,说明人们如何通过城市街道从一个地址导航到另一个地址。

闵可夫斯基(Minkowski)距离:该距离度量是欧几里得和曼哈顿距离度量的广义形式。下面公式中的参数 p 允许创建其他距离度量。当 p 等于 2 时,这个公式表示欧几里得距离,p 等于 1 表示曼哈顿距离 。

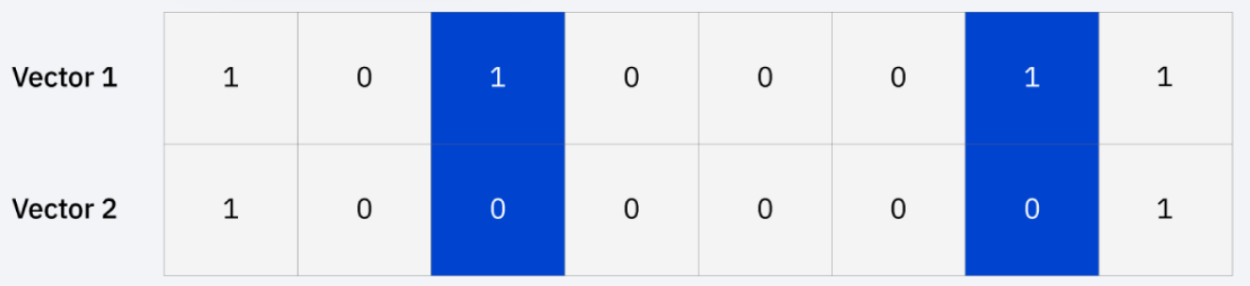
汉明(Hamming)距离:这种技术通常与布尔或字符串向量一起使用,识别向量不匹配的点。因此,它也被称为重叠度量。可以用以下公式表示:

例如,如果您有以下字符串,Hamming距离将为 2,因为只有两个值不同。
3. K
k-NN 算法中的 k 值定义了将检查多少个邻居以确定查询点的分类。例如,如果 k=1,实例将被分配到与其单个最近邻相同的类。定义 k 是一种平衡行为,因为不同的值可能会导致过拟合或欠拟合。较低的 k 值可能具有较高的方差,但较低的偏差,较大的 k 值可能导致较高的偏差和较低的方差。k 的选择将很大程度上取决于输入数据,因为有许多异常值或噪声的数据可能会在 k 值较高时表现更好。总之,建议 k 使用奇数以避免分类歧义,交叉验证策略可以帮助您为数据集选择最佳 k。
4. Operates
KNN 算法在执行时经历了三个主要阶段:
- 将 K 设置为选定的邻居数。
- 计算测试数据与数据集之间的距离。
- 对计算的距离进行排序。
- 获取前 K 个条目的标签。
- 返回有关测试示例的预测结果。
希望深入研究,可以通过使用 Python 和 scikit-learn 来了解有关 k-NN 算法的更多信息。以下代码是如何使用 kNN 模型创建和预测的示例:
from sklearn.neighbors import KNeighborsClassifier
model_name = ‘K-Nearest Neighbor Classifier’
`kNN`Classifier = KNeighborsClassifier(n_neighbors = 5, metric = ‘minkowski’, p=2)
`kNN`_model = Pipeline(steps=[(‘preprocessor’, preprocessorForFeatures), (‘classifier’ , `kNN`Classifier)])
`kNN`_model.fit(X_train, y_train)
y_pred = `kNN`_model.predict(X_test)
5. 应用
k-NN 算法已在各种问题中得到应用,主要是在分类中。其中一些用例包括:
数据集经常有缺失值,但 kNN 算法可以在缺失数据插补的过程中估计这些值。
使用来自网站的clickstream(点击流)数据,kNN 算法已用于向用户提供有关其他内容的自动推荐。这项研究表明,用户被分配到特定组,并根据该组的用户行为,为他们提供推荐。然而,考虑到 kNN 的应用规模,这种方法对于较大的数据集可能不是最优的。
它还用于各种金融和经济用例。例如,一篇论文展示了如何在信用数据上使用 kNN 可以帮助银行评估向组织或个人提供贷款的风险。它用于确定贷款申请人的信用状况。
kNN 还应用于医疗保健行业,预测心脏病发作和前列腺癌的风险。该算法通过计算基因的表达来工作。
kNN 还有助于识别模式,例如文本和数字分类。这对于识别在表格或邮寄信封上的手写数字特别有帮助。
6. 优缺点
就像任何机器学习算法一样,k-NN 也有其优点和缺点。根据实际情况,它可能是也可能不是最优的选择。
6.1. 优势
鉴于算法的简单性和准确性,它是新数据科学家将学习的首批分类器之一。
随着新训练样本的添加,算法会根据任何新数据进行调整,因为所有训练数据都存储在内存中。
kNN 只需要一个 k 值和一个距离度量,与其他机器学习算法相比,参数是很少的。
6.2. 不足
由于 kNN 是一种惰性算法,与其他分类器相比,它占用了更多的内存和数据存储。从时间和金钱的角度来看,这可能是昂贵的。更多的内存和存储将增加业务开支,而更多的数据可能需要更长的时间来计算。虽然已经创建了不同的数据结构(例如 Ball-Tree)来解决计算效率低下的问题,但根据业务问题,采用其他的分类器可能更好。
kNN 算法往往会成为维度灾难的受害者,这意味着它在高维数据输入时表现不佳。这有时也称为峰值现象,在算法达到最佳特征数量后,额外的特征会增加分类错误的数量,尤其是当样本尺寸更小。
由于“curse of dimensionality”(维度灾难),kNN 更容易出现过拟合。虽然利用特征选择和降维技术可以防止这种情况发生,但 k 的值也会影响模型的行为。较低的 k 值可能会过度拟合数据,而较高的 k 值往往会“平滑”预测值,因为它是对更大区域或邻域的值进行平均。但是,k 值太高,模型可能会欠拟合。








 苏公网安备32011502012024号
苏公网安备32011502012024号