引言
这个项目的启动是一位同事搞混了概念,误以为Python中的异步(async)自动等同于多线程。Python的异步事件循环是否能够与多线程协作。随着Python 3.13版本允许禁用全局解释器锁(GIL),这也是一个深入了解并更好掌握Python异步机制的良机。
我们的目标并不是为了打造一个适用于生产的、高性能的多线程异步解决方案来替代 asyncio库。
事件循环简介
David Beazley在2019年印度PyCon大会上的研讨会深入探讨了Python事件循环的运作方式,这里提供一个简明的概述。
事件循环可以类比为一个任务待办列表,我们按顺序执行列表中的每一个任务。与可能会中断任务的操作系统不同,Python的事件循环不会主动中断任务,而是等待任务通过使用await语句自愿交出控制权,或者自行完成。
值得注意的是,在Python中,每个线程都拥有自己的独立事件循环,这一点在设计多线程异步方案时必须考虑。
事件循环的工作原理
查看asyncio库的源代码,你会发现事件循环非常灵活,它通过BaseEventLoop类提供了一个抽象接口。我们不必手动实现所有需要的方法,而是可以从现有的_UnixSelectorEventLoop继承大部分方法,并根据需要重写方法。
对于本项目而言,事件循环的关键机制包括:
- 立即计划任务
像 call_soon和 run_forever这样的方法用于立即计划任务。call_soon将任务添加到待执行列表中,以便尽快执行。
run_forever方法让事件循环持续运行,处理任务和回调,直到显式停止。这个方法通常由 asyncio.run函数间接调用,该函数会创建一个事件循环,执行一个作为参数传递的协程,然后关闭事件循环。
- 计划未来任务
call_at函数允许你安排任务在将来的某个特定时间执行。例如:
await asyncio.sleep(10)
func()
在这里,Python会在 await asyncio.sleep(10)处暂停当前正在执行的协程,并继续执行下一个协程。当10秒钟过后,原先暂停的协程会被重新放回就绪队列。
这种机制的工作原理是,被暂停的协程会被添加到一个名为“调度堆”的数据结构中(BaseEventLoop._scheduled)。在这个堆中,任务会根据时间戳进行排序,确保堆顶的任务总是下一个即将就绪的任务。每当事件循环完成一轮任务选择和执行后,我们都会检查调度堆中是否有新的任务已经就绪,并将它们加入到就绪队列中。
- 处理网络操作
对于一个基础的FastAPI服务器来说,我们需要关注BaseEventLoop的几个关键网络操作:
i. 建立连接
create_connection:此方法用于启动TCP连接。像httpx和anyio这样的库利用它来执行异步网络操作。
ii. 接收数据
sock_accept和 sock_recv等方法负责管理传入的连接和数据接收。这对于FastAPI服务器监听并处理传入的请求是必需的。
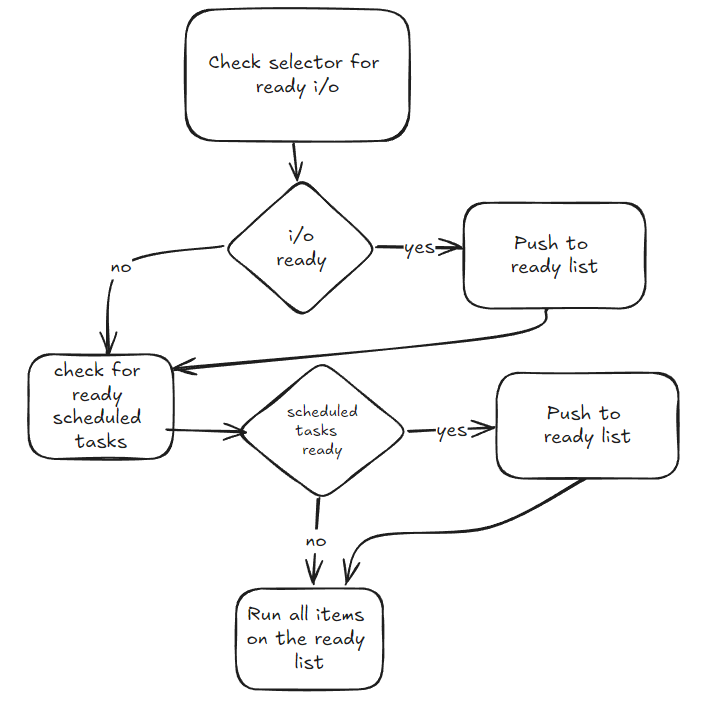
整合所有内容
在 BaseEventLoop的 _run_once方法中,事件循环任务的一个完整周期的运行流程如下:
- 首先,它会检查是否有文件描述符(例如文件或网络连接)已经准备好进行I/O操作,并将它们加入到就绪队列。
- 然后,它检查调度堆中是否有任务已经准备就绪,并将这些任务加入到就绪队列。
- 最后,它会逐个执行就绪队列中的所有任务。
下面的图表展示了这一流程:
我们如何确保线程安全并避免线程的忙等待问题?
我的做法
虽然不是十全十美,但我采取了以下措施:
BaseEventLoop使用一个简单的列表来管理就绪任务列表,而我选择了使用 queue.Queue。这样,当队列为空时,工作线程可以等待(即阻塞)。为了并行执行就绪列表中的任务,我们使用一个工作线程池从就绪队列中取出任务并执行它们。
通常情况下,每个工作线程都会有自己的事件循环,这可能会导致当一个任务在运行中想要调度其他任务时出现问题。为了避免这种情况,并让所有工作线程共享同一个事件循环,我编写了一个自定义策略(实际上就是创建事件循环的机制),它允许我重用现有的事件循环。
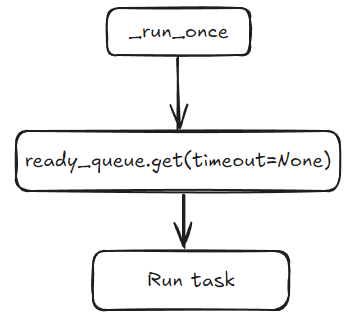
为了避免在两个不同的队列(就绪队列和计划队列)上阻塞就绪队列工作者,我们将引入一个专门的“计划线程”来简化任务管理。
在更新后的实现中,我们将使用 queue.Queue来替代原有的_scheduled列表。call_at方法会将任务放入这个队列,然后计划线程将从队列中取出任务进行处理。
这个计划线程将维护一个本地堆,根据任务的预定时间来组织任务,确保最接近就绪时间的任务始终位于堆顶。计划线程将在_scheduled队列上等待,使用与堆顶任务的下一个就绪时间相等的超时时间。当任务准备就绪时,计划线程会将其从堆中移除,并放入就绪队列。

由于选择器接口的工作机制,网络操作是这种方法遇到一些挑战的领域。问题的核心在于,调用_selector.select并不会移除已经准备好的I/O事件。换句话说,如果你连续多次执行_selector.select,每次都将返回相同的已准备好事件列表。在多线程环境下,这可能导致不同的线程试图处理同一个事件,从而引发问题。
为了应对这一挑战,我采用了一个解决方案:由一个独立的线程来调用_selector.select,并将事件添加到就绪队列中。虽然这种方法在一定程度上有所帮助,但它并非无懈可击。网络线程可能仍然会认为某些事件已经就绪,直到它们真正从就绪队列中被处理,这可能会导致一些不必要的错误。尽管存在这些问题,但产生的错误并不会导致严重后果,因此我决定继续采用这种设置。我计划在未来的项目中彻底重写IO方法,以便更有效地解决这些问题。

需要的调整
asyncio.tasks.Task的设计是为了防止单个事件循环同时执行两个任务。具体来说,在 __step方法中,如果事件循环尝试并行执行两个任务,_enter_task和 _leave_task函数会报错。我们没有直接删除这些函数,而是通过重写它们的定义来避免错误。最终,为了使用我们自定义的任务定义,我们可以在自定义的事件循环中重写 create_task方法。
结果
总的来说,自定义的事件循环在处理常规异步任务,如 call_soon和 call_at时,运行得很顺畅——这方面没有问题。
然而,网络方面带来了一些小麻烦。虽然请求能够通过,但在多个线程处理同一事件时,我们遇到了一些非致命的错误。这正是我之前提到的 _selector.select的问题。
潜在的问题是什么?
没有免费的午餐,这种方法有什么缺点呢?
首先,编写异步代码的人通常不需要担心锁定共享资源,因为一次只会运行一个函数。允许任务并行运行意味着你需要重新考虑这一点。这对FastAPI服务器来说影响不大,因为如果你本来就打算用多个工作进程来提供服务,你的代码可能已经是无锁的了。但对于普通的异步代码,你可能需要在共享资源上添加互斥锁,并更加注意竞态条件。
如果你将这种方法与纯异步或纯多线程相比较,这种方法有助于在处理混合了网络调用和CPU密集型任务时更好地利用CPU。例如,采用纯多线程方法,你需要足够的线程来确保那些阻塞在网络调用上的线程不会冻结整个服务器。同样地,采用纯asyncio方法,一旦遇到CPU密集型任务,你的服务器在此期间将无法处理新的/其他请求。








 苏公网安备32011502012024号
苏公网安备32011502012024号