论文
Genomic insights into local adaptation and future climate-induced vulnerability of a keystone forest tree in East Asia
论文中提供的代码
https://github.com/jingwanglab/Populus_genomic_prediction_climate_vulnerability/blob/2d314a9618a4e85d26030897c5b296dea5284e35/7-Genetic_offset/1GF.R#L3
没有找到论文中的数据
搜索了一下相关教程,找到了一个提供数据的教程
https://github.com/eriqande/merida-workshop-2022/tree/main
这个教程里写道这个分析还可以预测snp位点的重要性,有时间看看其中提到的论文
(这个github主页上还有好多其他教程)
这里分析需要准备两个数据
一个是环境数据,行是群体,列是环境变量,这里的群体是根据地理位置定的,在同一个区域内就是一个群体,这个群体的环境数据是一样的
另外一个数据是等位基因频率表,按照不用的群体算等位基因频率(这里没有搞懂是需要用突变基因型的等位基因频率还是用参考基因型的等位基因型频率)
利用vcf文件计算不同群体等位基因频率
如果有vcf文件按照不同的群体计算等位基因频率,使用plink2,准备一个群体分组文件
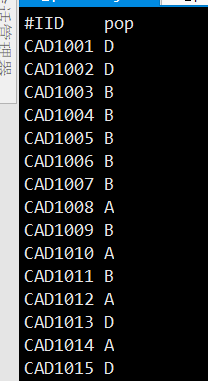 image.png
image.png
这个需要有表头
命令
~/biotools/plink2/plink2 --vcf ../rMVP/smoove_filtered.vcf --freq --pheno pheno02.txt --allow-extra-chr --allow-no-sex --loop-cats pop
最后的pop对应的群体分组文件里第二列的列名,这个根据自己的数据修改
输出结果是每个群体单独输出一个文件
 image.png
image.png
计算的是突变的等位基因频率
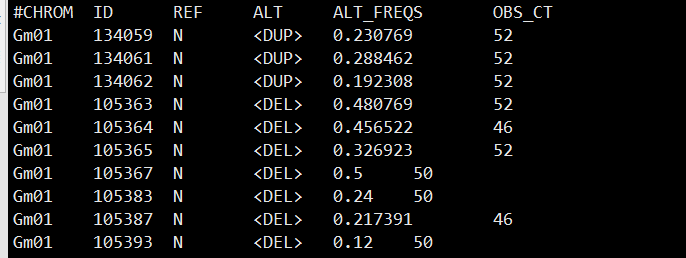 image.png
image.png
多个群体自己写代码合并
gradiantForest R包安装
install.packages("gradientForest", repos="http://R-Forge.R-project.org")
分析代码
library(gradientForest)
library(tidyverse)
path<-"D:/Jupyter/IAAS/reference/LEA变异和环境因素关联/merida-workshop-2022-main/"
Gwifl<-read_csv(paste0(path,'data/6.0/wiflforest.allfreq.sample.csv'))
Ewifl<-read_csv(paste0(path,'data/6.0/wiflforest.env.csv'))
nSites<-21
lev <- floor(log2(nSites*0.368/2))
lev
wiflforest<-gradientForest(cbind(Ewifl,Gwifl),
predictor.vars=Ewifl %>% colnames(),
response.vars=Gwifl %>% colnames(),
ntree=10,
transform = NULL,
compact=T,
nbin=101,
maxLevel=lev,
trace=T)
环境变量的重要性排序
plot(wiflforest,plot.type="Overall.Importance")
这里怎么把数据提取出来自己作图,暂时没有搞明白
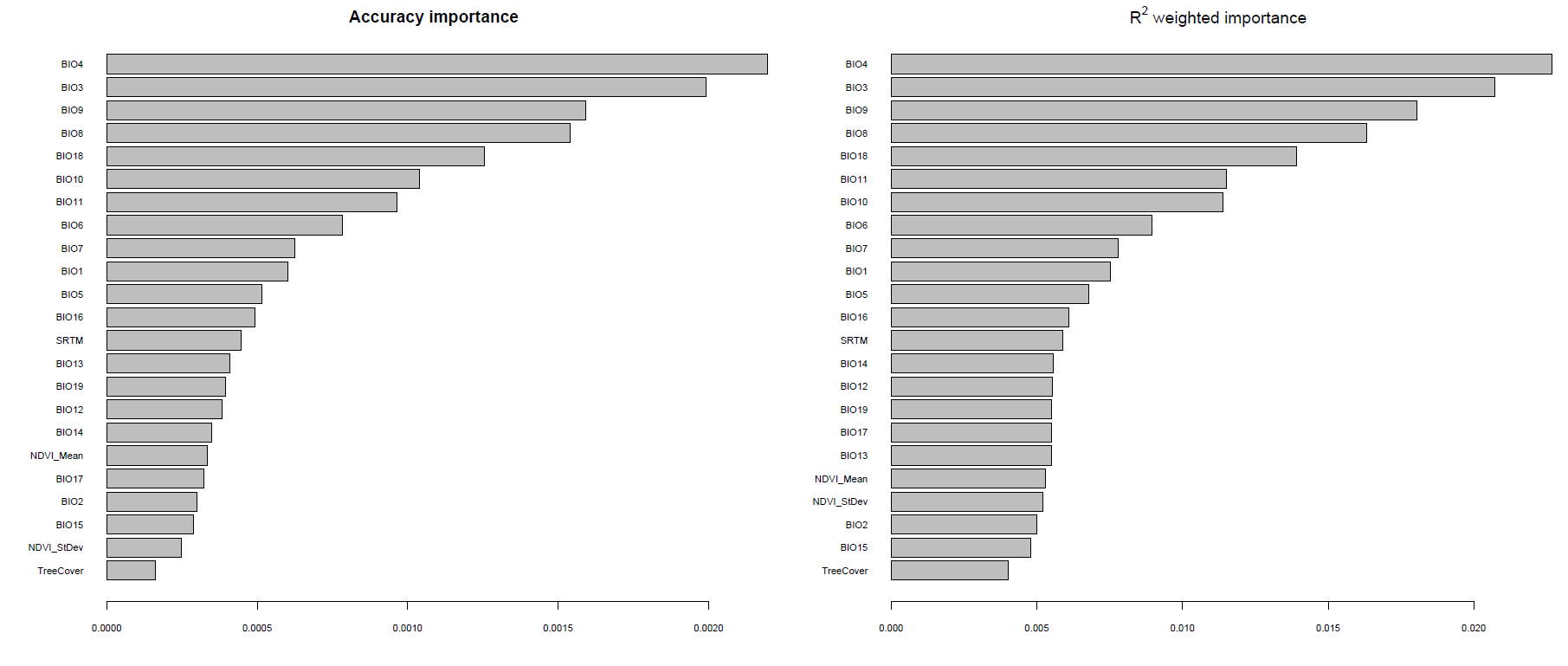 image.png
image.png
欢迎大家关注我的公众号
小明的数据分析笔记本
小明的数据分析笔记本 公众号 主要分享:1、R语言和python做数据分析和数据可视化的简单小例子;2、园艺植物相关转录组学、基因组学、群体遗传学文献阅读笔记;3、生物信息学入门学习资料及自己的学习笔记!





 苏公网安备32011502012024号
苏公网安备32011502012024号