引言
在互联网上分享,我得先声明:我使用git的方法来源于过去12年在小型(不足50人)工程团队的工作经验。在这些团队中,我们始终使用git和GitHub;所有的更改都在分支上进行,通过pull request提出,最后合并到主分支。特别是近几年,自从GitHub推出了squash-merging功能后,我们就开始使用它。
好了,言归正传,以下是我使用git的方法。
技术细节
我始终将所有内容都放在git中管理。无论是大型还是小型的副项目,无论是否完成或被遗弃,它们都存储在git仓库里。每当我创建一个新文件夹时,执行 git init总是我的首要步骤。我不明白,既然我能使用git,为何还要选择不使用它。
在我的命令行提示符中,git信息是最关键的部分。缺少了它,我会感到不习惯。它会告诉我当前所在的分支,以及仓库是否有未提交的更改,也就是所谓的“脏”状态:
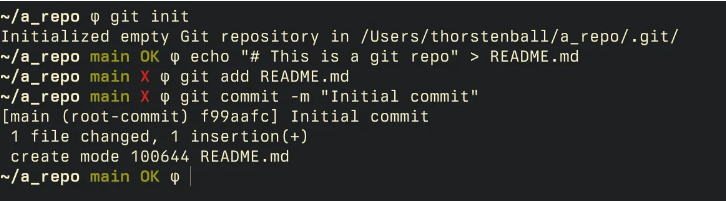
当有人请我帮忙处理一些git相关的事情时,如果我发现他们的命令行提示符中没有git信息,我通常会首先建议他们添加这部分内容。
我几乎99.9%的时间都是在命令行界面(CLI)中使用git,从未尝试过git的图形用户界面(GUI),也觉得没有必要去尝试。
唯一的例外是:git blame。对此,我总是使用内置的编辑器支持或GitHub的界面。之前,我使用vim-fugitive的blame功能长达十多年,而现在则是我们为Zed添加的git blame支持。
我使用git别名和shell别名,就像未来可能的关节炎在我身后低声对我说“很快”,时刻提醒我不要浪费每一个击键。这些别名存储在~/.gitconfig和我的.zshrc文件中。根据atuin的统计,我最常用的别名是:
gst - for `git status`
gc — for `git commit`
co — for `git checkout`
gaa — for `git add -A`
gd — for `git diff`
gdc — for `git diff —cached`
我经常使用这些命令,它们已经变成了我的肌肉记忆,我几乎不需要思考就能直接敲出来。特别是 gst命令,它是用来查看 git status的——我经常用它来确认我刚才的操作是否成功。比如,我添加了一些文件后就会运行 gst来检查,如果我使用 git add -p部分添加了一些文件,我就会运行 gst和 gdc来查看,如果我用 git restore恢复了一些文件,或者用 git stash暂存了一些更改,之后我也会运行 gst来确认。
以下是一个实例,展示了我是如何检查我刚刚做的更改,将它们加入暂存区,以及提交它们的过程:
~/code/projects/tucanty fix-clippy X φ gst
# [...]
~/code/projects/tucanty fix-clippy X φ gd
# [...]
~/code/projects/tucanty fix-clippy X φ gaa
~/code/projects/tucanty fix-clippy X φ gst
# [...]
~/code/projects/tucanty fix-clippy X φ gdc
# [...]
~/code/projects/tucanty fix-clippy X φ gc -m "Fix clippy warnings"
~/code/projects/tucanty fix-clippy OK φ gst
# [...]
为什么呢?我其实不太确定原因——可能是因为git命令没有给我足够的反馈,也可能是因为提示信息没有完全展示我需要的一切,我没有图形用户界面(GUI),而 gst命令实际上充当了这个角色?
我每天都在 ~/.githelpers文件中使用 pretty_git_log这个函数上百次。我是从Gary Bernhardt的一个屏幕录制中得到这个函数的,并且在过去12年里一直没有对它进行过任何修改。这个函数的输出看起来是这样的:
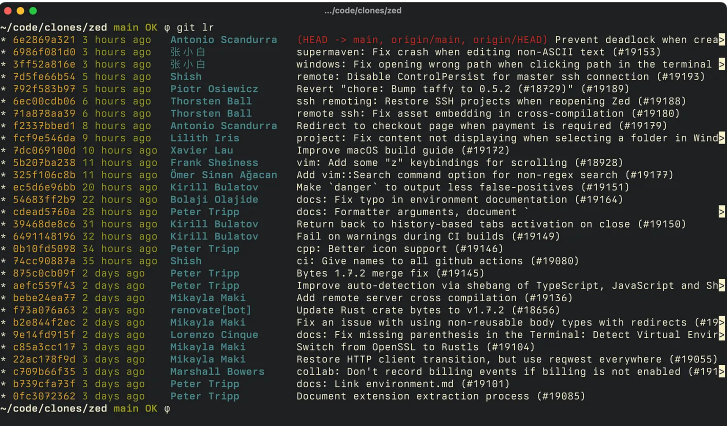
提交
我决定提交什么以及提交的频率,主要是基于我工作的仓库主分支上最终呈现的内容。是单次提交?还是压缩后的提交?或者是一系列提交?这些就是我努力优化的目标。
主分支上的内容需要满足:
- 其他人能够轻松理解,视为一个独立的变更。
- 可撤销的。如果在做变更时犯了错误,合并后才发现,我能否用
git revert命令来撤销这个变更?还是说这会连带撤销其他12个无关的变更,而这些变更很可能不是问题?
- 可二分查找的。如果在过去的一周中,我们发现主分支上出现了一个回归,我们能否通过逐个检查每个提交并测试它们来轻松找到这个回归?还是会最终只能大致指出“这个提交引入了它”,而实际上这个提交涉及了3000行的变更,包括更新OpenSSL依赖、更改市场文案、调整HTTP客户端的超时设置、添加数据库迁移、更改业务逻辑和更新默认日志记录器?这是我想避免的情况。
我认为这三个目标不可能总是100%实现,但我会尽量记住这些核心思想——事情是否容易撤销?是否容易作为潜在的回归来调试?——这影响我决定是将内容放在单独的pull request中,还是单独的提交中。
我尽早且频繁地提交。我对提交的理解就像视频游戏中的快速存档。你成功躲过了角落里的三个僵尸?快速存档。你修复了一个棘手的bug,尽管还不太明白改动的原理但它确实有效了?快速存档。先快速存档,然后再考虑如何正确地处理。
在我看来,提交和它们在我分支中的历史是可以修改的。只要我还没有请求别人审查,只要它们还属于“我”,我总是可以重写、压缩、重新基线化它们。
为什么?因为在我工作的几乎所有仓库中(我贡献的开源仓库除外),最终出现在主分支上的是合并后的pull request,而不是单独的提交。
所以我随心所欲地提交,然后在确保合并后的pull request易于理解、可撤销和可二分查找方面进行优化。
拉取请求
合并的pull request比分支上的单独提交更为重要,因为它们最终会进入主分支,这正是我想要优化的部分。
如果我们在合并时采用压缩提交的方式,那么一个PR合并后只会有一个提交,我会关注这个单一提交的清晰度、可理解性、可撤销性和可二分查找性。
如果我们不采用压缩提交,而是将分支上的所有提交都合并到主分支,我会关注这些提交。在这种情况下,我可能会在我的分支上进行交互式变基,按需将我的提交压缩成单个工作单元,以确保它们易于理解、撤销和查找。
代码审查有时会打破这个规则。因为审查者或同事的需求优先于我自己的。例如,如果PR是逐个提交审查的,我会在每个提交上投入精力。如果PR作为一个整体变更审查,只涉及两个文件中的三行修改,我会添加一个“修复格式”的提交,而不会太在意提交信息。
尽管如此,我始终坚持的一般原则是:我只关心最终的PR,它如何被审查,以及合并后会变成什么样子,而不是导致审查和合并的单个提交。
我会尽早开启PR。一旦我有第一个提交,我就会开启PR。以前我会在PR标题前加上“WIP”来标记这些尚未完成的PR,但现在GitHub有了草稿状态。我早早开启它们,因为一旦我推送代码后,CI就会开始运行,即使我继续工作,我也能得到来自长时间运行的测试套件、代码检查和样式检查等CI流程的反馈。
我对pull requests的准则是:小PR,积极合并。它们可能只有3行,有时300行,但基本上不会是3000行。如果一个PR开放超过一周,那就是一个警示信号。
例如,假设我正在开发一个功能,改变用户设置在用户界面中的显示方式。在开发过程中,我意识到我需要改变用户设置的解析方式,这只是一个两行的更改。我会将这个两行的更改单独放在一个PR中,即使我是在UI更改中发现需要做这个更改的。为什么?因为如果两天后有人说“我们的设置解析器有问题”,我想能够直接指向UI更改或解析更改,并撤销其中一个。
变基
我会将我的PR变基到主分支上,而不是将主分支合并到我的分支中。为什么?因为当我使用 git lr(我的别名,用于查看我分支上的git日志)时,我只想看到我分支上的提交。我认为保持在最新的主分支上进行变基更清晰。我不喜欢我的分支上有合并提交。交互式变基还允许我查看所有我做的提交,并了解分支上的内容。
当我变基时,我不担心破坏原始的、未被篡改的提交历史吗?再说一次:工作单元是合并的PR,我不在乎我分支内的提交是否反映了实时发生的事情。重要的是最终出现在主分支上的内容,如果我们使用压缩提交,那么所有那些未被篡改的提交历史反正也会丢失。
但是,再次强调,审查和审查者的要求会做出例外——我有时在我的分支上进行交互式变基,以压缩或编辑提交,使它们更容易审查(对我和其他人来说),尽管,再次强调,我知道那些提交将在两小时后被压缩。
即使我是唯一一个在这个项目上工作的人,甚至如果我会永远是唯一一个在这个项目上工作的人,我也在我的副项目中使用pull requests。我不是对每个变更都这样做,但有时,因为我喜欢在GitHub的UI中跟踪一些更大的变更。我猜我确实使用了一个UI?
提交信息和拉取请求信息
我重视提交信息,但不会过分纠结于细节。我不太在意那些前缀和固定格式。我更看重的是信息是否写得清晰明了。我曾读过Tim Pope在2011年左右写的《关于Git提交信息的说明》,从那以后就一直记在心里。
如果我们在合并时采用压缩提交的方式,那么PR的描述往往就是最终提交的信息,我会在PR的信息上多花些心思。
git提交信息或pull请求信息最重要的部分是变更背后的原因。我可以通过差异看到具体做了什么(尽管提交信息中的简短解释有时也有帮助),但当我阅读你的提交信息时,我更想知道的是你为什么要做这个改变。因为通常情况下,我们阅读提交信息,并不是因为发生了什么好事。
我认为像《Conventional Commits》这样的规范大多是在浪费时间。团队最终会为了很少的好处而争论正确的提交前缀。当我通过提交历史追踪一个回归时,我会查看每个提交,因为我们都知道,是的,一个回归甚至可能隐藏在一个[chore]:修复格式的提交中。
我有时会在提交信息或pull请求标题中添加前缀,比如“lsp: ”、“cli: ”或“migrations: ”。但我这么做主要是为了保持信息的简洁。“lsp: Ensure process is cleaned up”比“Ensure language server process is cleaned up”更短,基本上传达了同样的意思。
如果可能的话,我会尝试在PR中附上一个演示视频或者截图。一张截图胜过千言万语和无数指向其他票证的链接。截图就是证据。它证明了它确实修复了你所说的问题,证明了你实际上运行了代码。而且,添加截图所花费的时间通常比人们想象的要少。这里有一个例子:
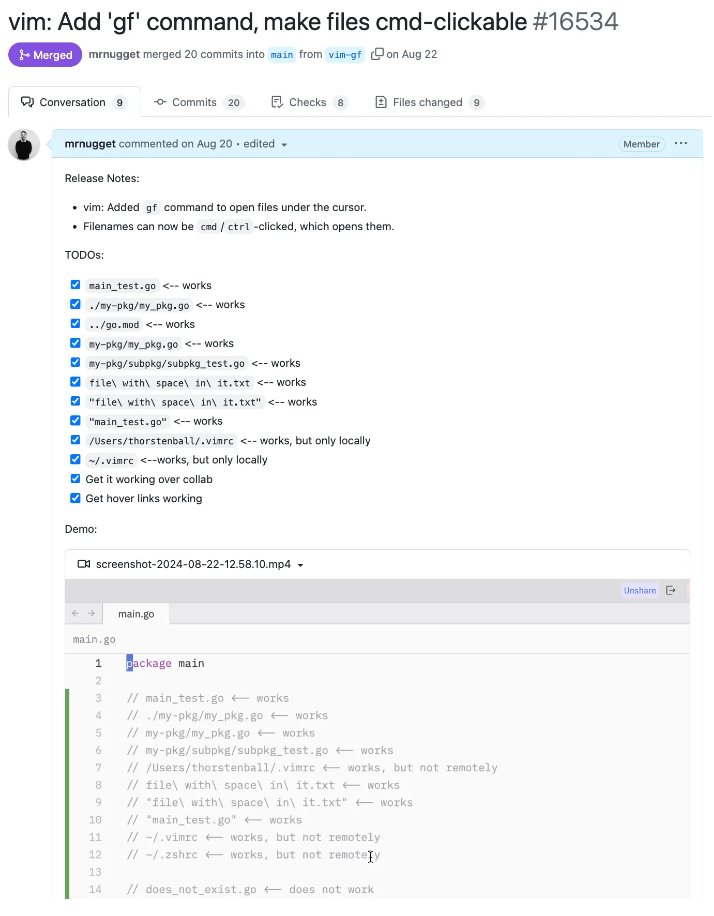
如果有必要,我会在提交信息中提及其他的提交和拉取请求。目的是:留下线索。我不会简单地写“修复了解析错误”,而是会详细说明“修复了解析错误,因为在3bac3ed的变更中引入了一个新关键字”。
在Zed,我们进行结对编程时,会在提交信息中添加 Co-authored-by: 名字 <邮箱>,这样提交就会与多个人关联。做法如下:
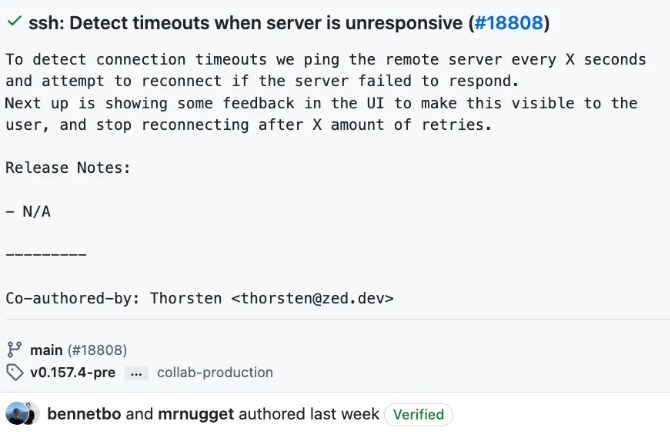
提交信息的编写,关键在于提供充分的上下文。我独自工作时的提交信息,与我在团队中工作时的提交信息是不同的。进行代码审查时的提交信息,又与结对编程时的有所不同。
你的提交信息是写给谁的,以及你为什么在那个时候写这个信息?这些问题应该决定你提交信息的内容。
当我在自己个人的仓库中独自工作,尝试让持续集成(CI)运行起来时,你很可能会看到我在主分支上使用单字母的提交信息。但即便只有我一个人工作,如果我修复了一个特别难缠的bug,我也会写一个详细的提交信息。当我与他人合作时,我会尽量编写那些能向他们解释我尝试做什么以及为什么这么做的提交信息。
代码审查
在请人审查我的PR之前,我会先在PR页面上自己查看差异。不知为何,当代码不在你的编辑器里时,你更容易发现更多的错误和遗漏的打印语句。
我尽量在CI通过后再请求审查。除非我已经知道如何修复CI,并且我们可以并行操作——审查者开始审查的同时,我去修复CI。
当我审查别人的代码时,我总是尽量检出代码,运行它,并测试它是否真的像PR信息中所说的那样工作。你会惊讶地发现,很多时候它并没有做到。
工作流程
当我和别人一起工作时,我遵循的标准流程是这样的:从主分支创建一个新分支,开始工作,尽早且频繁地提交代码,及时推送更改,尽早开设一个草稿拉取请求,完成工作后,确保分支中的提交是合理的,然后请求审查并合并。
而我一个人工作时,我几乎总是在主分支上提交,并且每次提交后都会推送。
有时在某个分支工作时,我会发现需要在另一个分支上新建一个提交,以便将其作为一个独立的拉取请求。这里我采用多种策略。
- 使用
git add -p选择我稍后想在这个分支(比如分支A)上提交的内容,然后 git stash这些更改,切换到另一个从主分支分出的新分支B,在那里提交,然后推送。
- 使用
git add -p并 git commit我想要保留在当前分支上的更改,然后将其他想要放在另一个分支上的更改 git stash起来,切换到目标分支,git stash pop并提交。
- 使用
git add -p并 git commit -m “WIP”我想要保留在当前分支上的更改,然后将其他想要在另一个分支上的更改 git stash起来,切换到目标分支,提交这些更改。然后回到原始分支,通过 git reset —soft HEAD~1撤销“WIP”提交,继续工作。
- 使用
git add -p选择我想要移动到另一个分支的更改,然后 git stash,接着 git reset —hard HEAD,放弃我在该分支上所做的其他所有更改,因为它们不值得保留。然后切换到目标分支,git stash pop并提交。
- 有时我甚至会把我想要的更改分成同一分支上的两个提交,然后切换分支,使用
git cherry-pick将其中一个提交挑拣过去,回到旧分支,执行 git rebase -i并删除已经移动过去的提交。
我如何选择一种策略而不是另一种?这取决于我想要在另一个分支上做的更改的规模,以及我工作目录中未提交的内容有多少。
我对分支名称不太挑剔,只要它们有点意义就行。我使用GitHub UI来概览我当前开放的拉取请求(这个URL是Raycast中的一个快速链接,所以我可以在Raycast中输入“prs”快速打开它)。这帮助我了解哪些PR正在进行中,哪些准备合并。
我要么通过点击推送到GitHub后显示的URL来创建拉取请求,要么运行 gh pr create -w命令来创建。这是我使用GitHub CLI的主要场景。
我也用 gh在开放的拉取请求分支之间切换,特别是当我检出贡献者的拉取请求时,它们位于一个分支中。
我还有这两个非常实用的别名,用于在开放的PR之间模糊切换,希望我能更经常地记住使用它们。
自从我上次因为git问题不得不删除并重新克隆一个仓库以来,已经过去很多年了。如今,我可以通过使用 git reflog,一些 git reset命令和一些临时解决方案,摆脱大多数可能出现的问题。








 苏公网安备32011502012024号
苏公网安备32011502012024号