为大型语言模型 (LLM) 提供服务需要多少 GPU 内存?
几乎所有的大型语言模型(LLM)面试中,都会频繁地出现一个问题:“要运行一个大型语言模型,需要多大的GPU内存?”这个问题并非随意提出,它实际上是衡量你对于这些强大模型在实际生产环境中部署和扩展能力理解程度的重要标准。无论是使用GPT、LLaMA还是其他任何大型语言模型,掌握如何估算所需的GPU内存非常关键。不管你面对的是7B参数的模型还是更大规模的模型,正确地确定硬件规格以支持这些模型都是至关重要的。
接下来,[将](https://masteringllm.medium.com/how-much-gpu-memory-is-needed-to-serve-a-large-languagemodel-llm-b1899bb2ab5d "Source")深入探讨相关的数学计算,以帮助你更有效地估算部署这些模型所需的GPU内存。
## GPU 内存估算公式
要估计服务大型语言模型所需的 GPU 内存,您可以使用以下公式:
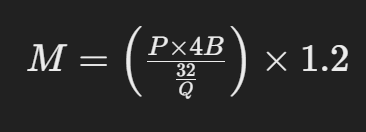
- M 代表 GPU 内存的大小,单位是吉字节。
- P 指的是模型中包含的参数总数。
- 4B 指的是每个参数平均占用的存储空间,为 4 个字节。
- Q 表示加载模型时使用的位数,可以是 16 位或者 32 位。
- 1.2 表示在计算中加入了 20% 的额外空间以应对可能的需求。
## 分解公式
- 模型参数量 (P):这个指标反映了你的模型规模。比如,如果你使用的是 LLaMA 模型,它包含 700 亿个参数,那么这个参数量就是 700 亿。
- 参数内存需求 (4B):通常情况下,每个模型参数需要 4 个字节的存储空间,这是因为浮点数通常需要 4 个字节(即 32 位)来表示。如果你采用的是半精度(16 位)格式,那么所需的内存量会相应减少。
- 参数位宽 (Q):这个值取决于你是以 16 位还是 32 位的精度来加载模型。16 位精度在许多大型语言模型的应用中较为普遍,因为它在保证足够精度的同时,能够降低内存的消耗。
- 额外开销 (1.2):乘以 1.2 的系数是为了增加 20% 的额外空间,以应对在模型推理过程中可能需要的额外内存。这不仅仅是为了安全起见,更是为了确保在模型执行过程中,激活操作和其他中间结果的内存需求得到满足。

## 计算示例
假设您想要估计为具有 700 亿个参数(以 16 位精度加载)的 LLaMA 模型提供服务所需的内存:
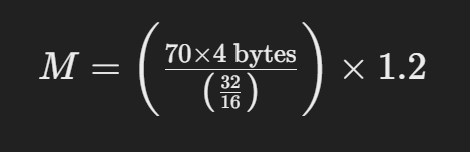
简化为:
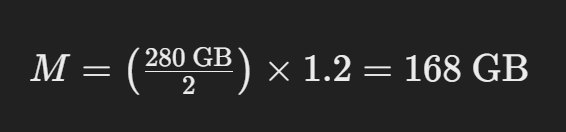
此计算结果告诉您,您将需要大约 168 GB 的 GPU 内存来为 16 位模式下具有 700 亿个参数的 LLaMA 模型提供服务。
## 实际意义
深入理解并运用这个公式,并非仅仅是理论上的探讨;它在实际应用中具有重要影响。例如,单块 NVIDIA A100 GPU,尽管配备了 80 GB 的显存,但仍然不足以支撑该模型的运行。为了高效地处理内存需求,至少需要两块 A100 GPU,每块都具备 80 GB 的显存容量。

精通这项计算技能,你将能够在面试中回答这个关键问题,并更为关键的是,防止在部署过程中出现成本高昂的硬件限制。当你下次规划部署时,你将能够准确估算出为有效运行你的大型语言模型所需的 GPU 内存量。
## 总结
本文强调了为大型语言模型正确配置GPU内存的重要性,并提供了一个详细的公式来帮助读者进行估算。通过实例计算和实际应用的讨论,文章指导读者如何在面试和部署中避免硬件问题。同时,提供了额外的学习资源和课程,以帮助读者更深入地了解LLM。
页:
[1]